
之前对于并发和异步讲得比较多,今天讲一下更常见的缓存应用架构。
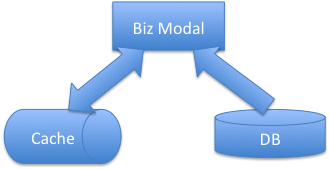
我们先看一个简单的架构
请求数据的流程图
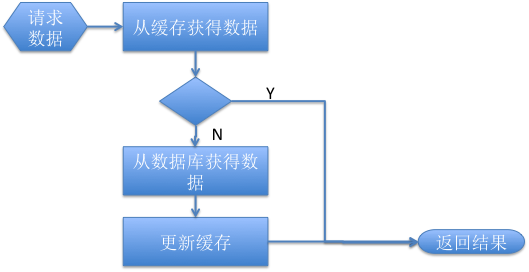
这里有几个要点
- 引入了缓存,减少了对数据库对访问(当缓存命中时)
- 当缓存不命中时,立刻进行补偿(读取数据库,更新缓存)
局限性
- 要求缓存数据结构与数据库表结构对应,无复杂计算。如果有复杂计算,当缓存失效同时并发访问,会导致服务器cpu耗尽。
- 缓存失效时,总会访问到数据库,随着并发请求的数量增大,数据库的负担也会增大
针对以上的局限,在复杂计算情况下,我们会把计算的结果保存到缓存,得到架构二
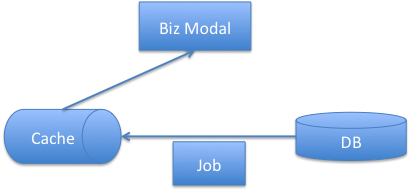
在这个架构下,我们引入一个定时运行(也可以是事件触发运行)的job,读取数据库的数据,进行计算后存放到缓存。保证缓存的数据始终有效(数据永不过期),应用层的访问不会穿透到数据库。
这个架构的优点很明显
- 数据库得到了保护,只有job访问数据库,数据库不会因为并发访问的数量增加而负载增加
- 应用层不含有补偿逻辑,简化了开发
然而这个架构包含致命缺陷,导致无法实际使用,这个缺陷就是“假设缓存是可靠的”。这与缓存高性能低可靠的设计原则是背离的,我们无法在系统中假设缓存可靠,保证缓存可靠的成本是运维部门无法承受的。
于是,结合之前两个架构的优点,我们得到了架构三
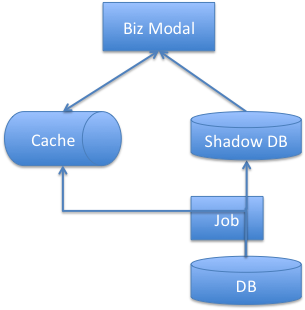
和架构二比较,我们引入一个shadow DB,这个db的表结构和缓存完全对应。然后我们的job,同时更新shadow DB和缓存的数据。我们的应用层如果访问缓存失败,到shadow DB去补偿
优点:
- DB得到了保护,访问不会穿透
- 假设缓存不可靠。缓存过期或者缓存服务宕机,压力只会传导到不影响业务的shadowDB
- ShadowDB和缓存可以独立扩展,应对更大的访问量
缺点:
- 引入了shadowDB,需要开发相应的(并不复杂的)逻辑
理解了这个缓存模块的设计,可以根据业务需要在系统中堆叠更多缓存层级