
这里主要介绍几种常见的架构设计理论和原则,常见于大中型互联系统架构设计。
一、CAP理论
1.1、什么是CAP?
著名的CAP理论是由Brewer提出的,所谓CAP,即一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)。
- Consistency(一致性):更新操作成功并返回客户端完成后,分布式的所有节点在同一时间的数据完全一致(All nodes see the same data at the same time)。这里的一致性,一定要和传统的RDBMS中的事务一致性区分开。
在传统的RDBMS中,事务具有ACID4个属性,即原子性(Atomicity),一致性(Consistency),隔离性(Isolation)和持久性(Durable)。
ACID是关系型数据库的最基本原则,遵循ACID原则强调一致性,对成本要求很高,对性能影响很大。
- 原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
- 一致性(Consistency):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
- 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性(Durability):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
MIT的Gilbert和Lynch在证明CAP的过程中改变了Consistency的概念,也就是将Consistency转化为Atomic。Gilbert认为这里所说的Consistency其实就是数据库系统中提到的ACID的另一种表述:一个用户请求要么成功、要么失败,不能处于中间状态(Atomic);一旦一个事务完成,将来的所有事务都必须基于这个完成后的状态(Consistent);未完成的事务不会互相影响(Isolated);一旦一个事务完成,就是持久的(Durable)。
- Availability(可用性):读和写操作都能成功(Reads and writes always succeed)。
可用性是说服务能一直保证是可用的状态,当用户发出一个请求,服务能在有限时间内返回结果,所有的请求都能“成功”拿到对应的响应。
- Partition Tolerance(分区容错性):在出现网络故障导致分布式节点间不能通信时,系统能否继续服务(The system continues to operate despite arbitrary message loss or failure of part of the system)。
直观感受就是系统中节点crash或者网络分片都不应该导致一个分布式系统停止服务。
1.2、如何证明CAP?
CAP的证明很简单:
假设两个节点集{G1, G2},由于网络分片导致G1和G2之间所有的通讯都断开了。如果在G1中写,在G2中读刚写的数据, G2中返回的值不可能是刚刚在G1中的写值。对于分布式数据系统而言,分区容错性(Partition Tolerance)是基本要求,否则就不称其为分布式系统。
由于可用性(Availability)的要求,G2一定要返回这次读请求,因为分区容错性(Partition Tolerance)的存在,导致一致性(Consistency)一定是不可满足的。
CAP理论告诉我们,一个分布式系统不可能同时满足一致性,可用性和分区容错性这三个需求,三个要素中最多只能同时满足两点。
显然,任何横向扩展策略都要依赖于数据分区,软件架构通常必须在一致性(Consistency)与可用性(Availability)之间做出选择。
1.3、CAP的延伸BASE
BASE是Basically Available、Soft state、Eventually consistent三个词组的简写,是对CAP中C 和A的延伸。
- Basically Available:基本可用,即数据一致性能够基本满足二八定律,即至少保证80%一致性,剩下20%就不要过于纠结。
- Soft-state:软状态/柔性事务,即状态可以有一段时间的不同步。
在不过分追求数据一致性(强一致性)前提下可考虑软状态策略,例如把数据(State)缓存在客户端一段时间,在一段时间过后,如果客户端没有再次刷新状态的请求的话,就清除此缓存(Soft),这个状态就会消失。 - Eventual consistency:最终一致性,即在某一段短时间内允许数据不一致,但经过一段较长时间(这里的一段时间多数是业务能够容忍的延迟),等所有节点上数据的拷贝都整合在一起的时候,数据会最终达到完全一致。我用自己的经验和亲身实践证明,最终一致性贯穿着互联网尤其是电子商务类型的主要应用的生命周期。
BASE来自于互联网的电子商务领域的实践,它是基于CAP理论逐步演化而来,核心思想是即便不能达到强一致性(Strong Consistency),但可以根据应用特点采用适当的方式来达到最终一致性(Eventual consistency)的效果。BASE是反ACID的,它完全不同于ACID模型,牺牲强一致性,获得基本可用性和柔性可靠性并要求达到最终一致性。
CAP、BASE理论是当前在互联网领域非常流行的NoSQL的理论基础。
二、无共享架构
2.1、什么是无共享架构
无共享架构SNA(Shared Nothing Architecture),维基百科中的说明是:
“A shared nothing architecture (SN) is a distributed computing architecture in which each node is independent and self-sufficient, and there is no single point of contention across the system. More specifically, none of the nodes share memory or disk storage. People typically contrast SN with systems that keep a large amount of centrally-stored state information, whether in a database, an application server, or any other similar single point of contention.”
总结起来说,无共享架构是一种分布式计算架构,这种架构中不存在集中存储的状态,系统中每个节点都是独立自治的,整个系统中没有资源竞争,这种架构具有非常强的扩张性,目前在web应用中被广泛使用。
无共享架构的一个重要实践指导原则就是避免在互联系统中使用Session,因为实践已经证明,在一个集群分布式计算环境中,若Session状态维护在各个节点服务器上,为了保证状态一致性,节点间Session数据需要互相拷贝同步,严重影响性能,我们需要尽可能的改造现有架构不要使用Session。
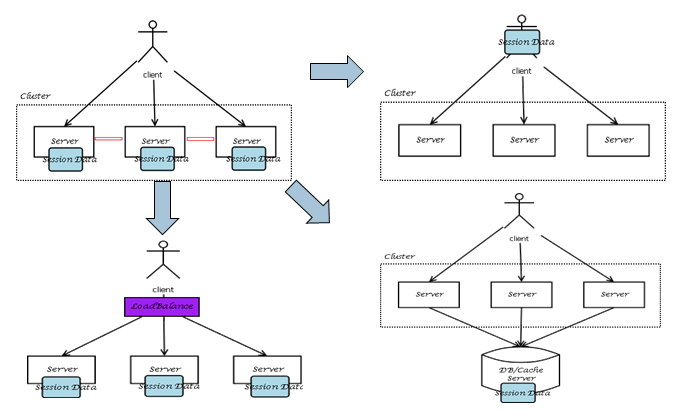
2.2、对比
shared-nothing、shared-memory、shared-disk是并行系统最常使用的模式。
shared-memory:多个cpu共享同一片内存,cpu之间通过内部通讯机制进行通讯
shared-disk:每一个cpu使用自己的私有内存区域,通过内部通讯机制直接访问所有磁盘系统
和shared-memory、shared-disk相比,shared-nothing优势明显,在针对多用户并行访问的时候,通过横向扩充资源,能够大大减少响应时间,提升整体吞吐量和效率。
2.3、分片
shared noting需要确立一种分片策略,使得依据不同的分片策略,减少资源竞争。
三种基本的分片策略结构:
- 功能分片
根据多个功能互相不重叠的特点进行分片,这种方式已经在ebay取得巨大成功。缺点也很明显,即技术人员需要深入理解应用领域,才能更好地分片。 - 键值分片
在数据中找到一个可以均匀分布到各个分片中的键值。 - 查表
在集群中有一个节点充当目录角色,用于查询哪个节点拥有用户要访问的数据。缺点在于这个表可能成为整个系统的瓶颈及单点失效点。
常见的开源DAL(如CobarClient、Fastser-DAL、Uncode-DAL等)实现的“路由”功能就有查表的影子。
2.4、现状
SNA目前广泛存在,重要的常见的应用包括Map-reduce、BigTable、Cassandra、MongoDB等。
三、ED-SOA架构
这种架构已经成为各种大中型企业的标配,尤其是业务和关系复杂的互联系统,没有ED-SOA的组织和调度,应用很可能经常面临着各种问题。
ED-SOA(Event Driven-Service Oriented Architecture),即事件驱动的面向服务架构。
SOA是系统组件化和模块化构建性理论,它的核心是暴露然后处理(expose and handle)。
EDA是以事件为核心,直观理解就是负责什么时候触发,然后做什么。
SOA使事件(Event)跨系统流动,系统组件之间通常是同步通信,可以采取事件机制使通信异步化,提高响应速度。
基于ED-SOA构建松耦合系统可以显著改善网站可伸缩性。
关于ED-SOA的理论和实践文章实在太多,本文就不再重复赘述了。
四、负载均衡
4.1、什么是负载均衡?
负载均衡(Load Balance),顾名思义,是把服务的并发请求均衡地负载到后端多个具有相同能力的服务进行处理分担,以廉价有效透明的方式扩展网络设备或服务的带宽,增加吞吐量,增强服务的整体处理能力,提供服务的灵活性和可用性。
常见的典型的负载均衡应用场景:
- web集群:将大量的并发访问或数据流量分担到多台节点设备上分别处理,减少用户等待响应的时间。
- MapReduce:单个重负载的运算分担到多台节点设备上做并行处理,每个节点设备处理结束后,将结果汇总,返回给⽤户,系统处理能⼒得到大幅度提高。
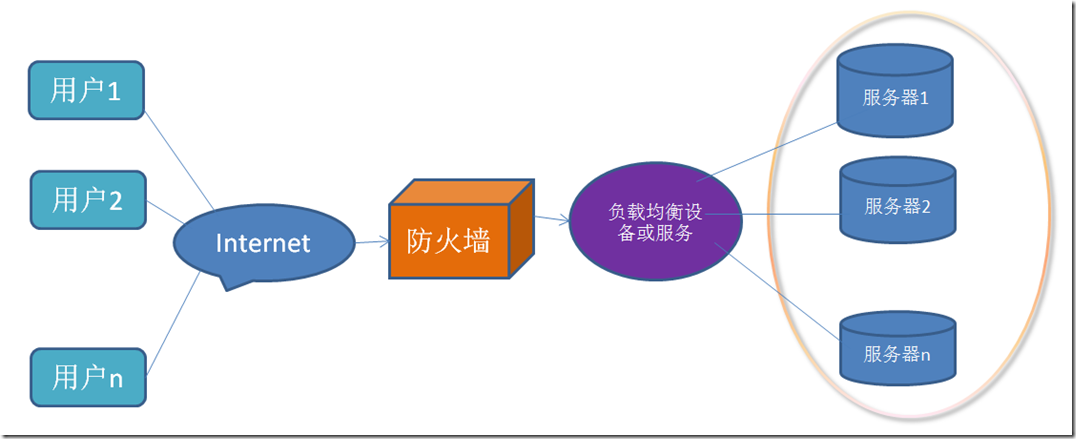
4.2、负载均衡算法
负载均衡算法是负载均衡设备(包括虚拟设备或相关软件)在执行负载均衡调度,选择具体处理的后端服务的时候使用的调度和分发的逻辑。
负载均衡的算法只是规定了调度和分发的逻辑,在不同的负载均衡方案中都可能使用相同和(或)类似的算法,它只是负载均衡方案的一部分。
常见的主流负载均衡算法包括:
4.2.1、轮询算法:Round Robin/Weight Round Robin Scheduling
轮询算法通过依次轮叫的方式依次将请求调度不同的后端服务器(Real Server)。通常可以分为普通轮询和加权轮询两种方式。算法的优点是简洁且无状态。
算法简单表示为:i = ( i + 1 ) mod n
4.2.2、Hash算法: 随机数Hash,Sources Hashing Scheduling
Hash算法,又叫取余算法。一般是对请求报文中的某项数据(key,一般常用客户端来源IP)计算Hash值,然后按机器数量(n)取模。
算法简单表示为:idx = Hash(key) % n
Hash算法中,Key的选择常用实践如下:
- 请求时间或随机数
特点是简单,具有一定分散性,但不稳定,一般用于要求不高的负载均衡场景。 - 来源IP
特点是简单。如果客户的分布比较广,这种方式分散性较好。但如果较多的客户请求来源于同一IP(公司网络通过路由器上网),分散效果较差。
大多负载均衡设备都支持这种算法,著名的nginx和LVS等软件也支持。
4.2.3、一致性Hash算法:Consistency Hash Scheduling
一致性Hash算法最常用于分布式缓存(如memcached、redis等)的定位,但同时也可以在系统或程序中用于负载均衡,该算法本来的意义就在于分散负载和快速定位。
推荐阅读:截至目前看过的一致性Hash算法最佳介绍请猛击这里。
4.2.4、最少连接或请求数: (Weight)Least Connection/Request Scheduling
最小连接调度是一种动态调度算法,它通过服务器当前所活跃的连接数来估计服务器的负载情况。算法主要逻辑是,调度设备或服务记录后端服务器接受请求的计数,每次请求总是发给计数最小的服务器处理。
4.2.5、最大空闲:Most idle First(基于监控CPU,内存,带宽等综合评估)
4.2.6、平均最快响应:平均最快响应
4.2.7、最少流量:Least Traffic Scheduling
还有一种常见的就是基于会话的负载实现,但是严格来说Session(一般用于WEB)不能算是算法。Session实现负载均衡的主要过程为:首次请求记录用户的SessionID,然后再通过轮询等算法选择后端服务器,如果用户后续使用同一SessionID发起请求,则无需再选择服务器,直接转发给前面根据SessionID找到的对应的后端服务器。
4.3、负载均衡模式
负载均衡模式主要是指在整体方案中选择从服务网络的哪个层次或哪个产品来实现负载均衡方案。
4.3.1、外部模式(RR-DNS)
RR-DNS,即DNS轮询模式,它的原理是利用DNS服务器支持同一域名配置多个独立IP指向,然后轮询解析指向IP实现多次访问的调度和分发,实现负载均衡。
它的主要特点为:
- 负载均衡实现与后端服务完全没有关系,有DNS在本地解析指向实现轮询调度。这个方面来看性能最佳效率最高。
- DNS服务无法检测到后端服务器是否正常,在TTL失效前,会一直指向失效的服务器,这就要求在实践生成中,必须解决后端服务器的高可用问题。
- 一般的第三方DNS服务提供商都支持该功能,但如果更新频率高或附带更新逻辑,一般会在系统内自键DNS服务,然后在注册为公共DNS服务。
4.3.2、应用层模式
a、什么是正向和反向代理?
正向代理:用户通过代理服务访问internet, 把internet返回的数据转发给用户。正向代理对于整个网络请求,它的角色实际是客户端,代理客户对外的访问请求。
反向代理:接受internet上用户的请求,转发给内部的多台服务器处理,完成后转发后端服务器的返回给对应的用户。反向代理对于整个网络请求,它的角色实际是服务器,代理接受(accept)所有用户的请求。
b、反向代理应用模式
常见的反向代理应用模式,比如通过 Apache, nginx等Web服务器软件实现WEB应用的负载均衡和高可用。
利用反向代理软件实现负载均衡是性价比较高的模式。
4.3.3、网络层模式
a、IP转换
IP转换模式的负载均衡一般是在网络的IP层实现,通过报文改写的方式实现VIP到多个内部IP的转发调度,以达到负载均衡的效果。 它的主要特点包括:
网络层方案,效率较高,稳定性较好;可与操作系统内核结合;工业级模式和方案;大部分商业设备和产品都以该方式为主;LVS的基本原理也类同。
b、IP转换之LVS
LVS(Linux Virtual Server),是中国人(98年)写的工业级的负载平衡调度解决方案,章文嵩博士是该开源软件创始人。也是目前业界最流行的软件方式实现负载均衡的模式之一。LVS也是利用IP转发的原理实现大多数有商业产品实现的能力,并做了部分优化,主要有三种模式的应用。
- 通过NAT(Network Address Translation)实现虚拟服务器(VS/NAT)
- 通过IP隧道实现虚拟服务器(VS/TUN)
- 通过直接路由实现虚拟服务器(VS/DR)
关于LVS的介绍文章非常多,这里就不再详细介绍了,推荐参考阅读<<构建高性能web站点>>和<<大型网站技术架构>>这两本书中关于负载均衡的部分章节。
c、IP转换之负载均衡设备
F5等负载均衡设备同样是在网络层实现负载均衡,但一般而言造价较为昂贵,性价比较低。
五、高可用系统设计
5.1、系统可用性
系统可用性定义:MTTF/(MTTF+MTTR) * 100%
MTTF: mean time to failure,平均失效前时间,也就是正常运行的时间
MTTR: mean time to restoration, 平均恢复前时间,也就是故障时间
系统高可用性(High Availability)通常来描述一个IT系统经过专门的设计,减少计划和非计划停工时间,保持其服务的高度持续可用性。
影响系统可用性的因素很多,包括硬件、软件、网络和环境(比如机房温度)等,除了常见的CPU、内存、IO、网络、锁等因素,还需要考虑各种支持设备和系统、非技术的因素,总之,系统可用性是一个综合因素影响的结果。
5.2、高可用的模式
系统高可用性的常用设计模式包括三种,包括:
5.2.1、主备(Active-Standby)
工作原理:主机工作,备机处于监控准备状况;当主机宕机时,备机接管主机的一切工作,待主机恢复正常后,按使用者的设定以自动(热备)或手动(冷备)方式将服务切换到主机上运行。一般需要人工干预才能回复初始状态。
5.3.2、互备(Active-Active)
工作原理:两台主机(A标记为主,B标记为备)同时运行各自的服务工作且相互监测情况,当任一台主机(A)宕机时,另一台主机(B,启用并标记为主)立即接管它的一切工作,保证工作实时可用
5.3.3、集群(Cluster)
工作原理:多台具有相同能力的服务同时对外提供透明服务,所有服务之间都是Active-Active关系,并分担处理服务请求,一般通过总控节点或集群软件(例如zookeeper等)进行高可用的控制。
5.3、高可用的设计
高可用的设计没有完美的标准答案。但是根据工程经验,我们可以总结出高可用设计的一个重要指标:
不要有单点。不要有单点。不要有单点。
强调了三遍,现在记住了吗?
如果是在设计开发实现和维护大中型web系统,通常我们会从互联系统中最容易出现问题,同时也最不容易横向扩展的节点下手(包括网络和存储系统),排查并解除系统中的薄弱环节,争取保证整个系统中绝不出现单点这一死角,或者出现单点,但也可以通过成熟的优化手段(缓存、队列、sharding、负载均衡和异地容灾等)实现高可用。
你可能还是会有疑问:是不是系统中没有单点了保证高可用了就一定不出事情了呢?
答案是,还是可能会出事,而且可能都是大事。今年的黑色五月份的几起重大IT事故,无情地告诉我们,再高明的设计,碰到物理破坏或者权限控制不当而误操作或者DDoS都有可能让开发和设计人员的所有心血付之东流。